Design for failure
Always anticipate that there will be FAILURES. Identify and address the Failure points in your applications
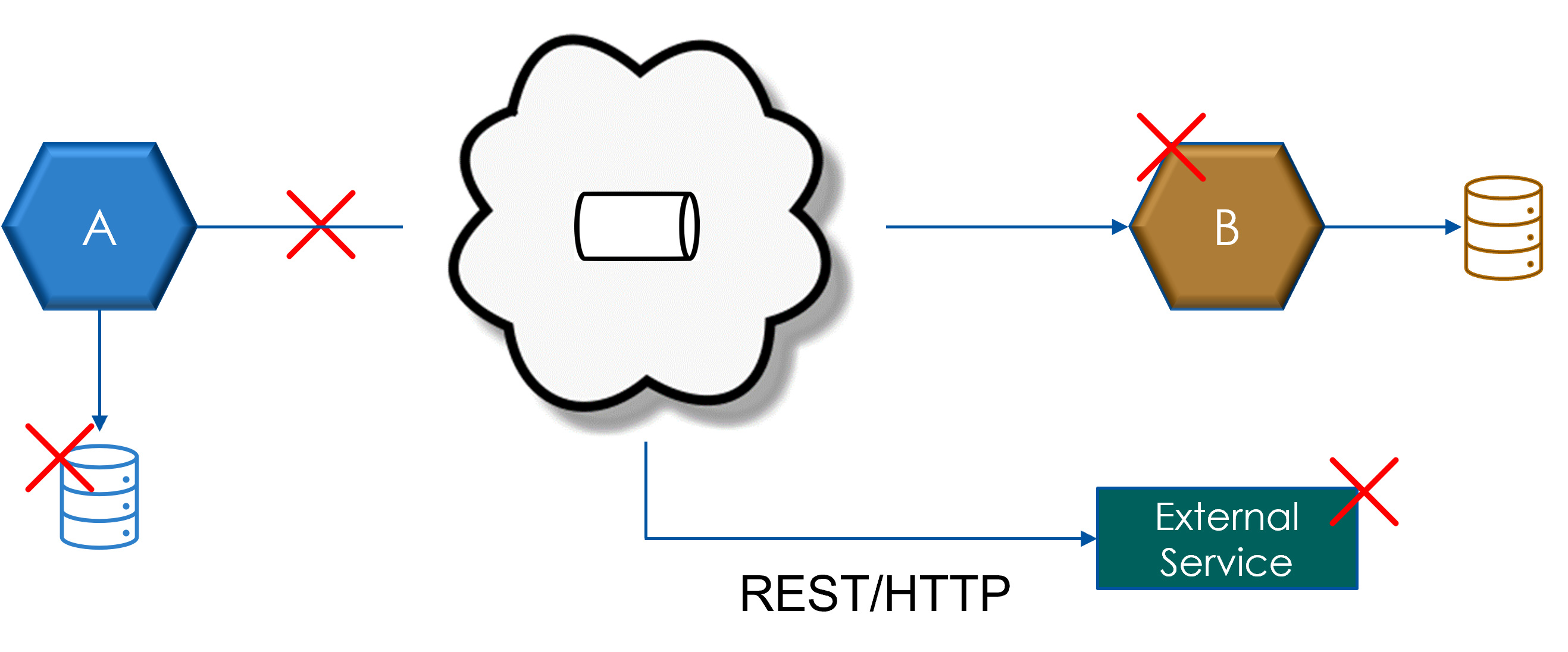
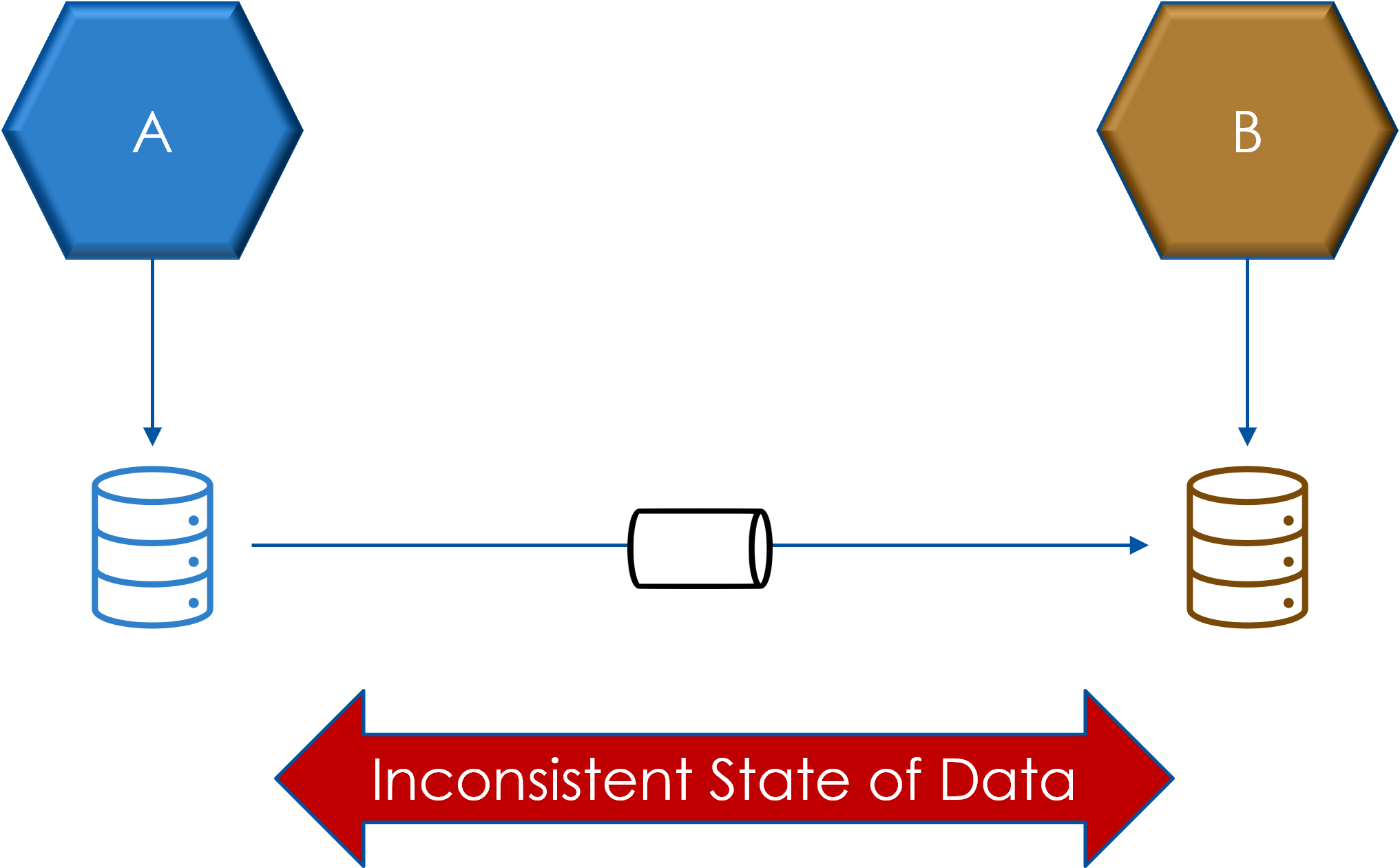
Streaming replication has challenges
Assume that there will be failures in replication
Assume there will be relication lag between source and target leading to stale data reads from target side
MUST handle:
- Loss of Message
- Producer may send duplicate messages
Pattern : Transactional write
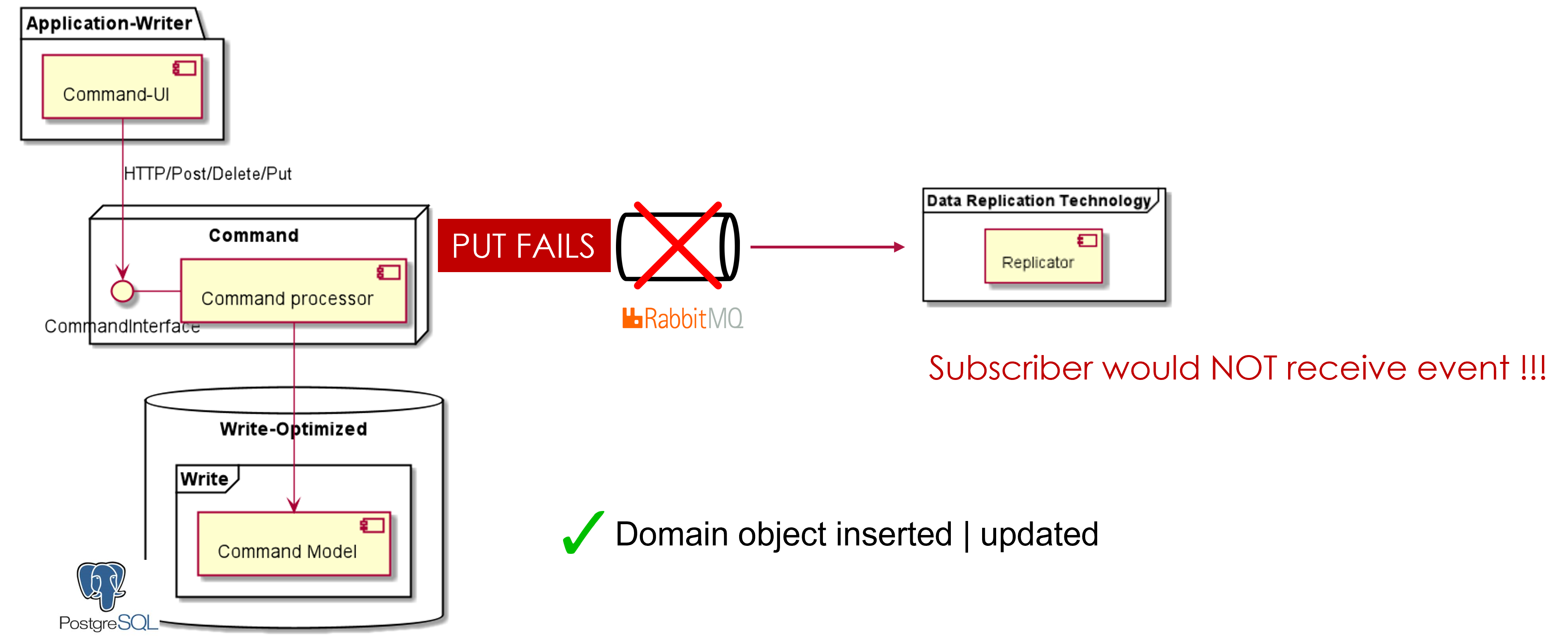
Scenario Write side updates the state of an aggregate in the database. There is a failure in emitting the event. As a result the Read side is unaware of the state change; now the 2 ends are inconsistent !!!
Options
- Use 2 phase commit
- Reliable Messaging Pattern a.k.a. Transactional Outbox Pattern
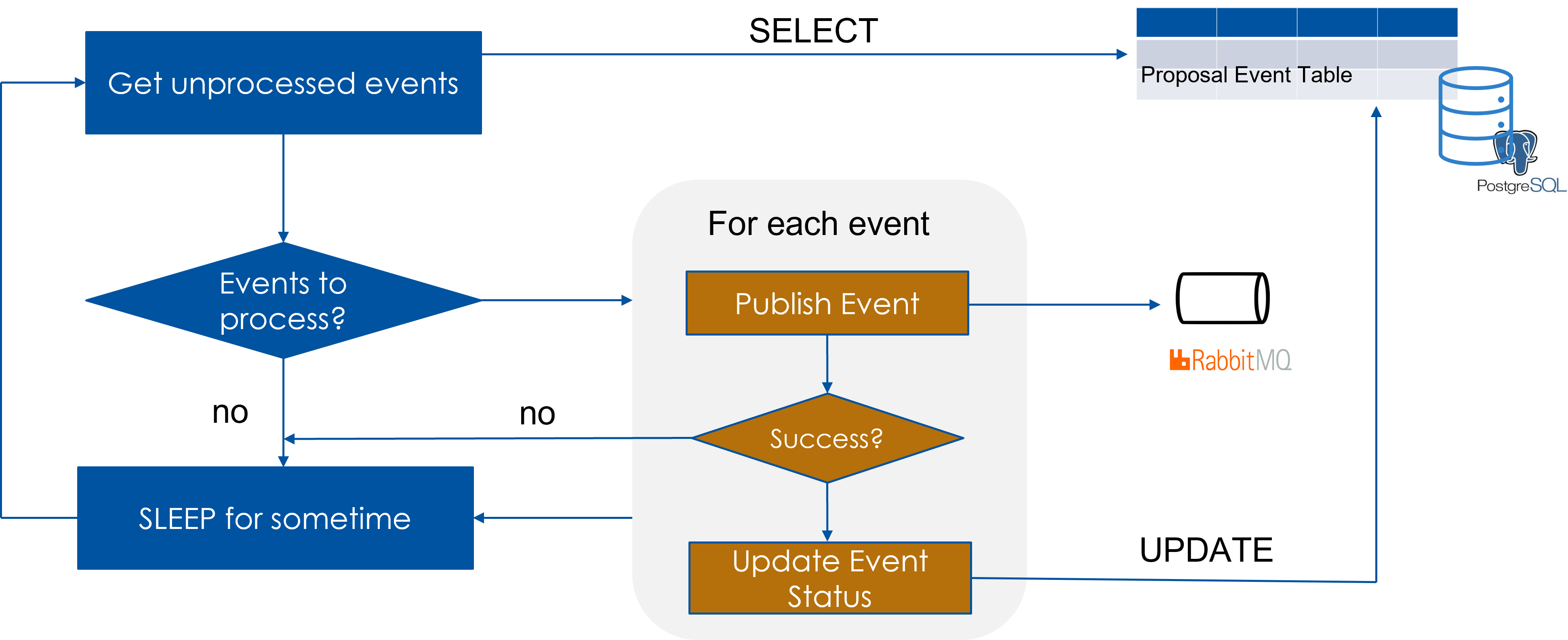
Reliable Messaging Pattern
Write domain object data & event data in the database with a local transaction and replay the events against queueing system in a separate | subsequent step.
- In a Local DB transaction:
- Update aggregate
- Add event information in a Event Table
- Run a job for publishing events
- Read unprocessed events from Event table
- Publish the event
- Mark event delivered only if successful
- Read side MUST be prepared to handle duplicate messages!!
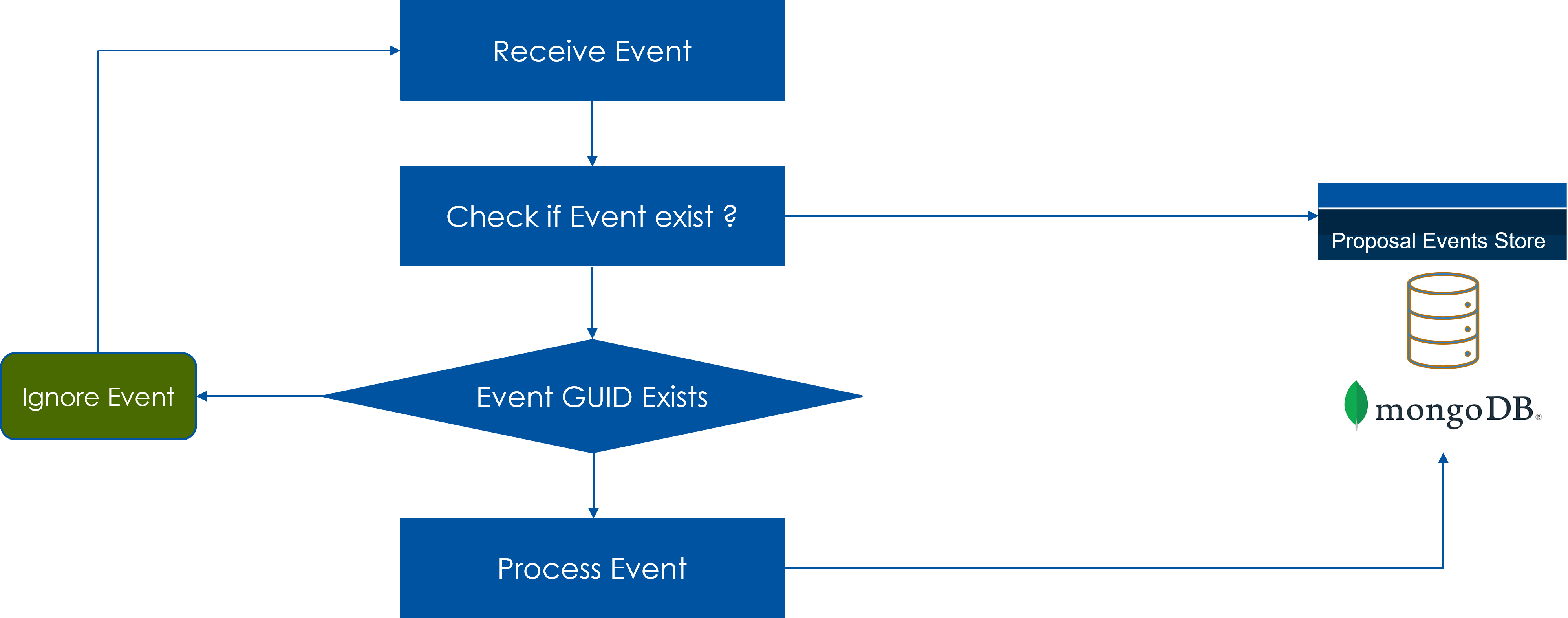
Pattern : Duplicate reads
- Read side should look for ways to make event processing idempotent
- Read side should be prepared for handling duplicates
- Write side assigns unique-identity to each message
- Read side maintains metadata for each event to avoid duplicate processing
Illustration depicts the logic in which event metadata is maintained in a MongoDb database. When event is received, Read side checks the metadata before applying the event.